
Robots vs. babies...and the winner is....
Or, what it takes to be a useful robot


For a robot to be useful, it needs to effectively perform a task with minimal supervision. For example, a robotic vacuum cleaner isn’t effective if it isn’t strong enough to suck the dirt from your carpet, or it misses spots, or isn’t charged when you need it. It needs too much supervision when it needs to be picked up before it falls down the stairs, or it gets stuck while vacuuming a shag rug (this also goes to effectiveness).
Putting aside task-specific requirements, for a robot to be effective under minimal supervision, it has to be able to:
navigate its environment
know where (and where not) to execute the task
adapt to changes in its environment
learn from experience and feedback
maintain the resources it needs to operate
These requirements each merit a future post. For now, I’ll share some context about the challenge they represent. How? By starting with an insult of course.
Robots aren’t babies
People generally don’t like it when you tell them they ‘act like a baby’. Shocking, right? But when it comes to robots, it’s a compliment. You see, robots are no match for a baby when it comes to learning about the physical world. Yann LeCun recently referred to this chart that tracks how infants develop their physical intuition:
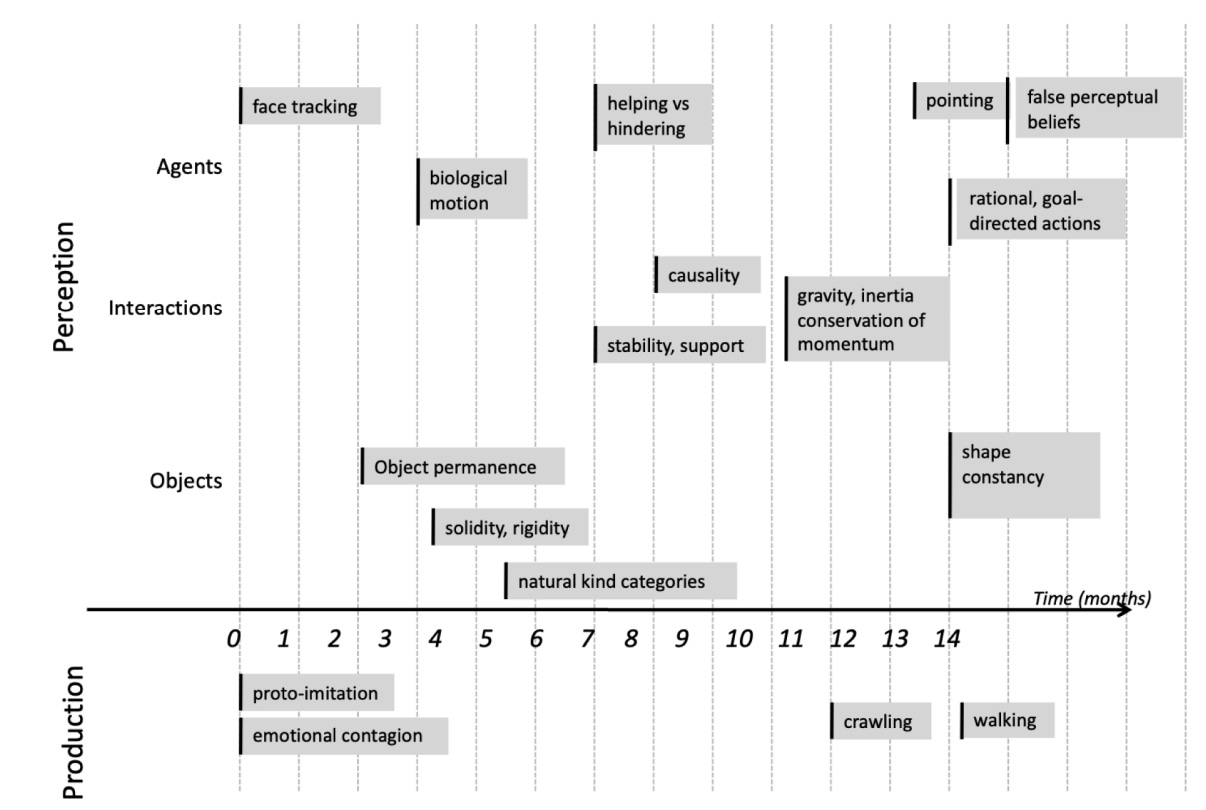
Each of these building blocks forms our ‘common sense’ about our physical world. And we figure it out without any experience to start with. It’s remarkable. A baby’s perception develops as she explores and interacts with her environment. She experiences the world through her senses, or putting it in ML-terms, she is trained on the dataset generated from her senses. So how large is her dataset?
Each eye transmits data to her visual cortex at a rate of a about 1 MB/s1. Assuming she is awake for 10h each day (babies like to sleep), her eyes generate 28TB of visual data in the first year. In 4 years her training data set is larger than the one OpenAI trained GPT-32 with! It takes a lot of data before she expects a cup will fall the table when pushed.

The type of data used for training also matters. GPT-3 is trained on a huge amount of text, and that helps when doing things like solving math problems. But robots have to navigate a 3D world with varying and unpredictable conditions like changing weather, lighting, new objects. Training a model on a large corpus of text isn’t going to cut it - you need video.
And there are other considerations like planning, remembering, and safety. So a lot of fun challenges ahead!
Progress
This week, I’ve set up a Jetson Orin Nano with an IMX-219 stereo camera. I’m planning to build the prototype around this hardware as it hits a sweet spot on price and capability. It took some tinkering but everything seems to be working now.
I’ve been auditing Deep Learning for Computer Vision (Stanford CS231N), and have set up Jupyter Notebook and have started on the first assignment. It’s really fun and I’m looking forward to going through the material in the coming weeks.
I have also been auditing Deep Learning I (Stanford CS230) to reinforce what I learn in CS231n and fill in gaps.
Cool stuff I’ve been reading/listening to/watching
Tensor Logic: The Language of AI - an interesting paper by Pedro Domingos about unifying logic programming and tensor algebra to make one AI language to rule them all. Or at least you should be able to better inspect and guard against things like hallucinations. Looking forward to kicking the tires when the language is released.
Cheeky Pint interview w/ Kyle Vogt - Kyle cofounded Twitch and Cruise. He’s now the CEO of The Bot Company which specializes in home robotics. He mentioned that robots have prioritized repeatability because of technology and application area (manufacturing). Modern robots prioritize adaptability in a changing home environment, and do so through neural nets.
I have very much been thinking along the same lines because of past experience: I worked with image recognition, but was discouraged by the accuracy and complexity of approaches at the time (SIFT feature detection, bag of words, Harris corner detection, etc) that didn’t seem to operate like our visual system. AlexNet winning the ImageNet competition in 2012 was a watershed moment showing that data combined with convolutional neural nets were a better approach to image classification. The old approaches are now obsolete. I see the same thing happening with robotics.
From Seeing to Doing - Fei-Fei Li’s keynote at NeurIPS was almost a year ago but feels very relevant today. She gives an overview of Visual Intelligence, a framework composed of:
Understanding - semantic labeling of the contents based on visible pixels which requires object recognition, segmentation, video classification, etc.
Reasoning - inferring or reasoning with information beyond visible pixels which requires understanding objects and their relationships.
Generation - creating new pixels or altering existing ones
She raises the ‘flat earth’ problem, where models are trained on data made up of 2D artifacts like images and text that doesn’t correspond to our 3D world.
She then extends the idea of Visual Intelligence to Spatial Intelligence in 3D.
She calls out the need (and work being done) to create an analogue of ImageNet that lets researchers and professionals benchmark approaches to achieve Spatial intelligence. She makes a very clear point that robotics research is focused on toy problems with simple environments and tasks, without standard benchmarks and that this doesn’t address challenges in the real world that is complex, dynamic, varied, and interactive.
Lots of good coverage on datasets to address some of these shortcomings, along with the research her group is doing. I’ve made a note to myself to follow up on some of these topics as they relate to the prototype. I’ll share what I learn. See you next week!